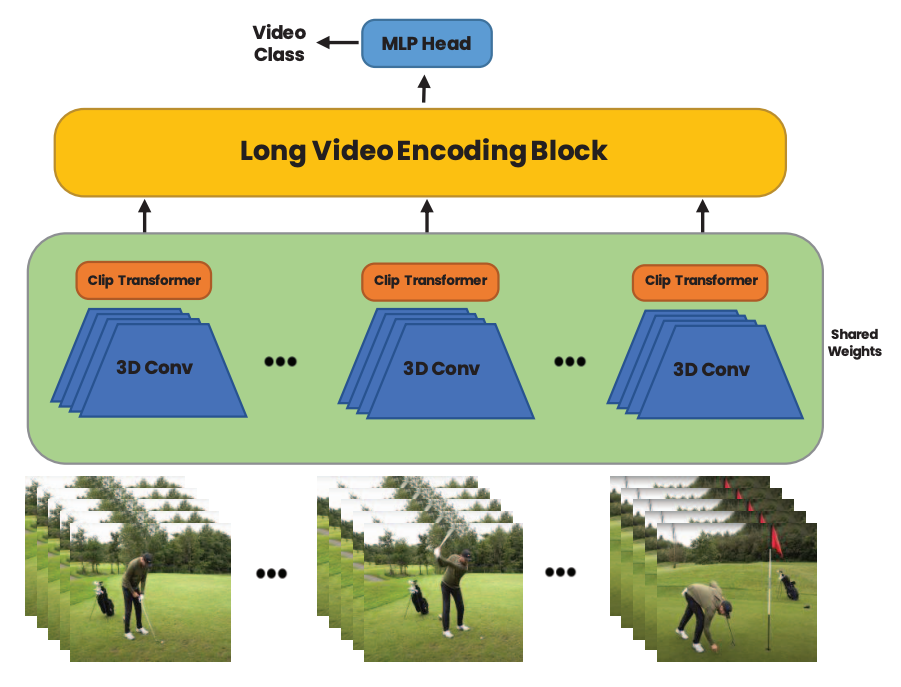
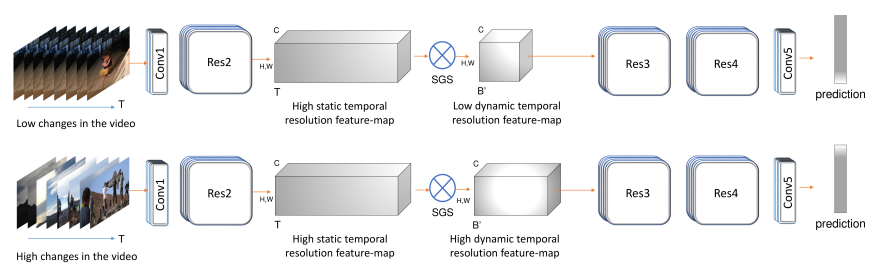
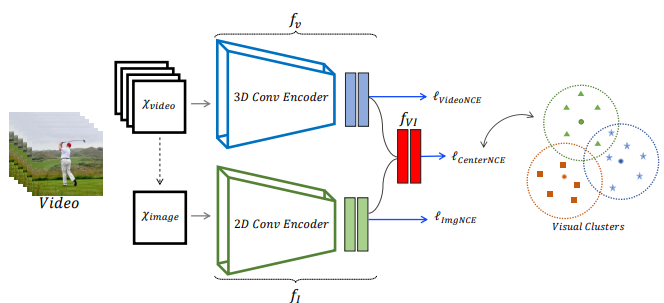
|
I am a scientist and PI at the Qatar Computing Research Institute (QCRI), where my research focuses on computer vision and multi-modal foundation models. Prior to joining QCRI, I was a Staff Research Scientist at Lunit, working on AI systems for cancer detection and prediction. I received my PhD from KU Leuven, under the supervision of Prof. Luc Van Gool, where I investigated multi-task learning for vision models on edge devices and large-scale holistic video understanding. Earlier in my career, I co-founded Sensifai, a computer vision startup dedicated to large-scale media archive monitoring. Email / CV / Google Scholar / Twitter / Github |

|
|
I'm interested in research and development in computer vision, deep neural networks, and foundation models. Currently, I'm working on multi-modal vision-language models on images, videos, and text in the humanitarian AI domain. |